Implementacija AI modela (engl. AI model deployment) je proces u kome se trenirani model pretvara u produkcioni servis koji konzistentno odgovara na zahteve aplikacija pod realnim opterećenjem. Obuhvata formiranje modela, serving infrastrukturu, rollout strategiju, monitoring i jasnu proceduru za rollback. Bez ovih elemenata, model je samo artifakt u registru, ne proizvod.
Najveći broj AI projekata ne propada na treningu, već ovde, između validnog .bin fajla i stabilnog endpoint-a. Po Gartner istraživanju koje IBM citira, oko polovine generative AI projekata nikada ne dođe do produkcije.
U nastavku saznajte više o tri sloja odluka koje MLOps tim mora doneti pre nego što model dođe do korisnika: kako servirati, kako rollout-ovati, gde hostovati.
Šta je deployment AI modela i zašto je različita od treniranja
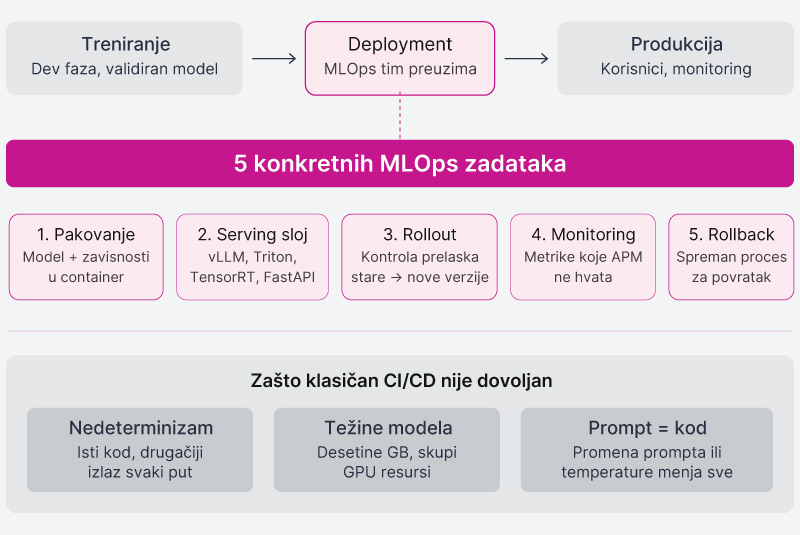
Deployment nije “deploy nedeljnog Python skripta”. Modeli su nedeterministički, težine dosežu do desetina gigabajta, GPU resursi su skupi i ograničeni, a kvalitet modela opada tokom vremena (drift) bez ijedne izmene koda. MLOps tim u ovom kontekstu radi pet konkretnih stvari: pakuje model i njegove zavisnosti u container, postavlja serving sloj (vLLM, TensorRT-LLM, Triton, FastAPI), kontroliše kako saobraćaj prelazi sa stare na novu verziju, prati metrike koje klasičan APM ne hvata, i drži spreman rollback proces.
Klasičan CI/CD nije dovoljan jer kod LLM-ova promena prompta ili temperature (tj nasumičnost teksta) menja ponašanje sistema bez izmene jednog reda koda. Tim koji izlazi iz razvojnog okruženja sa validiranim modelom i dalje ima posla: serving stack, rollout pattern i monitoring nisu nasleđeni iz dev faze, oni se postavljaju ovde.
Sloj 1 — Kako servirati: tipovi inference servisa

Pre izbora rollout strategije, bira se mod posluživanja. Različiti modovi imaju različite zahteve za infrastrukturu i različite tolerancije na rollout patterne iz sledećeg sloja.
Real-time inference (online API)
Model iza HTTPS endpoint-a, sinhroni request/response, milisekundna latencija.
Use case: chatbot, korisnički asistent, fraud screening u realnom vremenu, recommendation engine.
Zahtevi: GPU sa dovoljno VRAM-a za težine plus headroom za KV cache, autoscaling, low-latency mreža.
Ovo je najčešći mod za LLM-ove i primarno mesto gde se koriste rollout patterni iz Sloja 2.
Batch inference
Model obrađuje skupove podataka periodično.
Use case: noćni risk scoring u banci, klasifikacija arhive dokumenata, generisanje opisa proizvoda.
Infrastrukturni zahtevi su blaži, monitoring je drugačiji — prati se uspešnost batch run-a, ne p99 latencija po zahtevu.
Streaming inference
Kontinuirani tok podataka, near-real-time predikcije: Kafka ili sličan broker → model → sink.
Use case: detekcija anomalija u telemetriji, IoT pipeline-ovi, screening transakcija u toku.
Edge inference
Implementacija AI modela na uređaju (kamera, gateway, vozilo), interferencija bez povratne veze do data centra.
Use case: computer vision na proizvodnoj liniji, analitika maloprodaja, autonomna vozila.
Glavna zamka: rollout strategija mora podržati uređaje koji su povremeno offline ili imaju slabu vezu.
Izbor moda definiše šta uopšte može biti rollout strategija u sledećem koraku. Real-time servisi mogu sve patterne; batch i streaming sistemi se obično rolaju kroz blue-green ili shadow, kanari je teško pravilno postaviti.
Sloj 2 — Kako uraditi rollout: pet strategija implementacije AI modela

Kada nova verzija modela ide u produkciju, pitanje nije da li može da padne, nego kako ograničiti štetu kad padne. Sledećih pet pattern-a su industrijski standard, dokumentovani u AWS-ovom Prescriptive Guidance, svaki sa drugačijim trade-off-om između brzine i bezbednosti.
Blue-green deployment
Dva identična okruženja, blue (trenutni) i green (novi). Saobraćaj se prebacuje sa jednog na drugi u jednom trenutku, najčešće preko load balancer-a ili DNS-a. Rollback je instant — vraća se routing na blue.
- Kada aplikacija ne može sebi da dozvoli paralelne verzije zbog deljenog stanja, kompatibilnosti scheme ili vector store-a.
- Kada je potrebna instant rollback opcija.
- Kao prvi rollout pattern timu koji tek postavlja procese.
Trade-off: veći trošak, jer u trenutku prelaska imaš dupli kapacitet.
LLM-specifični problem: ako blue i green pišu u isti vector store, scheme migracije moraju biti backward-kompatibilne ili rollback ne radi.
Canary deployment
Nova verzija dobija mali procenat saobraćaja (5%, pa 10%, pa 25%), ostatak ide na staru verziju, postepeno do 100%. Default izbor za većinu LLM rollout-ova kada postoji dobar routing sloj.
Kada koristiti: kad vam je potrebna real-traffic validacija pre punog cutover-a. Kad imate metriku po varijanti i možete da uporedite performanse i kvalitet u istom okruženju.
Trade-off: traži zreliju routing infrastrukturu — service mesh tipa Istio ili Linkerd, ili ingress sa težinama.
Praktična napomena: uradite strukturisanje saobraćaja po tipu zahteva. Ako kanari dobije slučajno težu populaciju (duži kontekst, kompleksnija pitanja), signal nije validan.
Shadow deployment
Nova verzija prima kopiju produkcionog saobraćaja, ali njen odgovor se ne vraća korisniku — samo se loguje i upoređuje sa starom verzijom.
Kada koristiti: kao poslednja tehnička provera pre canary-ja, posebno kod modela visokog rizika u BFSI, zdravstvu i sličnim regulisanim domenima. Kada želite da uporedite dva modela na identičnoj populaciji bez otkrivanja korisnika.
Trade-off: visoki troškovi, jer plaćate inference za saobraćaj koji niko ne vidi. Ne dobijate user feedback signal, ali dobijate čist tehnički signal — latencija, throughput, razlike u outputu, error rate. Tipična sekvenca u zrelom timu: shadow → canary → full.
A/B testing
Dve verzije primaju saobraćaj paralelno sa namerom da se uporede po proizvodnoj metrici — konverzija, retention, satisfaction — a ne po stabilnosti.
Razlika u odnosu na canary je suštinska. Canary pita da li je nova verzija bezbedna za rollout. A/B test pita da li je nova verzija bolja. Nerazumevanje razlike izme]u ova dva je čest izvor pogrešnih odluka, jer signali koji se prate i pragovi za odluku nisu isti.
LLM-specifično: kvalitet LLM odgovora se ne svodi na jednu metriku. Treba pratiti više dimenzija (factuality, ton, latencija, regeneration rate) i imati definisane prioritete pre testa, inače će neka varijanta uvek pobediti po nekoj dimenziji.
Multi-armed bandit
Ruting automatski preusmerava saobraćaj ka boljoj varijanti tokom samog testa, umesto fiksne raspodele. Bandit algoritmi balansiraju eksploraciju i eksploataciju u realnom vremenu.
Kada koristiti: kada se cilj može izraziti kao jedna kontinualna metrika i kada je trošak suboptimalnog rutiranja visok. Tipičan primer: predlozi proizvoda gde svaki minut nedovoljno dobrog modela direktno gubi konverziju.
Trade-off: kompleksnija implementacija, rezultat koji je teže interpretirati nego A/B. Ne preporučuje se kao prvi pattern timu koji tek postavlja procese.
Svih ovih pet patterna Orion AI Factory podržava na produkcionom inference sloju bez izlaska iz domaće infrastrukture, što dovodi do trećeg sloja odluke.
Sloj 3 — Gde hostovati: javni API, privatni L3VPN ili on-prem

MLOps tim mora razumeti regulatorne i bezbednosne implikacije pre izbora arhitekture, a ne posle.
Javni HTTPS endpoint sa autoscaling-om
Klasičan model: namenski DNS, HTTPS terminacija, autoscale od 0 do N instanci. Pogodan za SaaS proizvode, javne chatbot-ove, B2C aplikacije, dev i staging okruženja. Limit: nije prihvatljivo za sisteme pod regulatornim okvirom Narodne Banke Srbije niti za one koji obrađuju lične podatke pod Zakonom o zaštiti podataka o ličnosti bez dodatnih tehničkih i ugovornih kontrola.
Privatna mreža (L3VPN, VRF, MPLS)
Inference sloj nevidljiv javnom internetu, dostupan samo preko privatne konekcije. Pogodno za bankarske i finansijske sisteme, državne i javne sisteme, zdravstvo, kritičnu industriju. Usklađen sa zahtevima NBS-a za upravljanje IT rizikom i podacima klijenata, kao i sa zahtevima organizacija koje moraju dokazati izolaciju AI workload-a.
On-prem ili sovereign cloud
Pun fizički nadzor nad modelima, container image-ima i podacima. Pogodno za organizacije sa zahtevom da AI model i njegov registar nikad ne napuste njihovu infrastrukturu — bankarski i finansijski sektor, industrije regulisane zakonom, razvojne timove koji rade na projektima sa osetljivom intelektualnom svojinom.
Trade-off: kompleksnija operacija u odnosu na javni cloud, ali eliminiše rizik izlaska podataka i intelektualne svojine van interne kontrole.
Sva tri scenarija mogu biti pokrivena lokalno, bez oslanjanja na strane cloud regione. To je suština ponude koju Orion AI Factory pravi za regionalne MLOps timove.
Šta sve treba pratiti nakon deployment-a
Bez monitoringa nijedna od gore navedenih strategija nije zaista završena. Tehničke metrike koje treba snimati od prvog dana: p50, p95 i p99 latencija, throughput u zahtevima po sekundi, GPU iskorišćenost, queue depth, error rate, KV cache hit ratio za LLM-ove. Metrike kvaliteta su drugačija priča — za LLM-ove relevantni signali su regeneration rate, abandonment, follow-up clarification; za klasifikatore tačnost, preciznost i recall na live golden setu, ne na trening setu.
Drift detection prati distribuciju ulaznih feature-a u odnosu na trening set i distribuciju output-a tokom vremena. Klasičan APM ovo ne hvata jer prati CPU i memoriju, ne distribucije podataka, kako je Galileo dokumentovao u svom MLOps vodiču.
Deploy događaji su poseban sloj telemetrije: koja verzija modela je u produkciji u svakom trenutku, ko je promovisao Canary u full rollout, kako se metrika menja oko deploy događaja. Rollback rules treba postaviti unapred — automatski okidači koji vraćaju prethodnu verziju ako p95 latencija ili error rate prekorači prag X minuta.
Praktična napomena koja se često ignoriše: monitoring se postavlja pre prvog deployment-a, ne posle prvog incidenta.
Kako odabrati strategiju za vaš tim
Ako tim tek postavlja procese i nema service mesh, blue-green je prvi izbor — naprednije strategije ostavite za fazu kada imate routing i opservabilnost koji ih podržavaju. Ako imate zreo routing sloj i normalan LLM use case bez specijalne regulative, canary je default.
Ako je domen visokog rizika (banka, javni sektor, zdravstvo), standardna sekvenca je shadow → canary → full, sa rollback pravilima postavljenim u shadow fazi. Ako pitanje više nije “da li radi” nego “da li je bolje”, najpogodniji je A/B test sa unapred definisanom primarnom metrikom. Multi-armed bandit ima smisla samo kada je cilj jedan jasan biznis KPI i kada tim već ima A/B kulturu — ne kao prvi pattern.
Često postavljana pitanja
Šta je deployment AI modela?
Deployment AI modela je proces puštanja treniranog modela u produkciono okruženje gde služi realnim aplikacijama i korisnicima preko stabilnog endpoint-a. Obuhvata pakovanje modela u kontejner, postavljanje serving infrastrukture, rollout strategiju, monitoring i procedure za rollback.
Koja je razlika između blue-green i canary deployment-a?
Blue-green prebacuje sav saobraćaj sa stare verzije na novu u jednom trenutku, dok canary postepeno povećava udeo saobraćaja koji ide na novu verziju (5%, 25%, 50%, 100%). Blue-green je brži ali nudi manje validacije pre punog cutover-a; canary daje signal o realnom saobraćaju pre nego što on pređe.
Šta je shadow deployment i kada se koristi?
Shadow deployment je strategija u kojoj nova verzija modela prima kopiju produkcionog saobraćaja, ali se njen odgovor ne vraća korisniku, već se samo loguje i upoređuje sa starom verzijom. Koristi se kao poslednja tehnička provera pre canary-ja, posebno za modele visokog rizika u finansijskom sektoru, zdravstvu i sličnim zakonski regulisanim industrijama.
Zašto AI projekti zapnu između pilota i produkcije?
Najčešći razlozi su nepostojanje serving infrastrukture sa pravim SLO-vima, nedostatak monitoring kvaliteta odgovora (ne samo latencije), nepostavljen rollback proces, i regulatorne prepreke koje se otkrivaju tek pri prelasku na produkciju. Trening daje model, ali ne i produkcioni servis.
Da li se canary i A/B test razlikuju?
Da. Canary postavlja pitanje “da li je nova verzija bezbedna za rollout”; A/B test postavlja pitanje “da li je nova verzija bolja po proizvodnoj metrici”. Tehnički izgledaju slično jer oba dele saobraćaj, ali signali koji se prate i odluke koje slede su različite.
Zaključak
Deployment AI modela je trostruka odluka, ne jedan korak: mod posluživanja, rollout pattern, lokacija hostinga. Svaki sloj nosi tehničke i regulatorne implikacije koje se ne nasleđuju iz dev faze. Tim koji ovo postavi pre prvog produkcionog modela radi mnogo brže od tima koji to otkriva u toku incidenta. Ako gradite produkcioni AI servis u Srbiji, produkcioni inference sloj Orion AI Factory-ja pokriva sva tri sloja unutar domaće, regulatorno usklađene infrastrukture.




