

Datum: 23.07.2026
Šta su AI agenti: vodič za kompanije u 2026.
AI agent je softver zasnovan na velikom jezičkom modelu (LLM) koji samostalno planira i izvršava zadatke kako bi postigao zadati cilj...
Blog
04.06.2026.
RAG arhitektura (retrieval-augmented generation) je obrazac za izgradnju AI sistema u kom veliki jezički model ne odgovara samo na bazi podataka na kojima je trenirao, već prvo pretraži eksternu bazu znanja firme i tek onda generiše odgovor. Cilj je da odgovor bude tačan, aktuelan i potkrepljen vašim podacima, a ne halucinacijama modela.
Većina tekstova o RAG-u objašnjava komponente, vektorsku bazu, embedding model, LLM, ali preskače teže pitanje za enterprise: gde sistem fizički živi, ko vidi podatke i koliko košta da radi pouzdano. Zato sve više firmi u regionu razmatra suverenu AI infrastrukturu kao alternativu javnim cloud servisima, posebno kada se RAG primenjuje na poverljive interne dokumente.
U ovom tekstu objašnjavamo kako RAG zaista radi, kojih pet slojeva čini enterprise arhitekturu, zašto je odluka „gde ovo hostujemo“ često važnija od izbora modela, i kako EU AI Act i GDPR utiču na to kuda podaci putuju pri svakom upitu.
RAG sistem se uvek odvija u dve odvojene faze: jedna se dešava unapred (offline), druga pri svakom upitu (real-time).
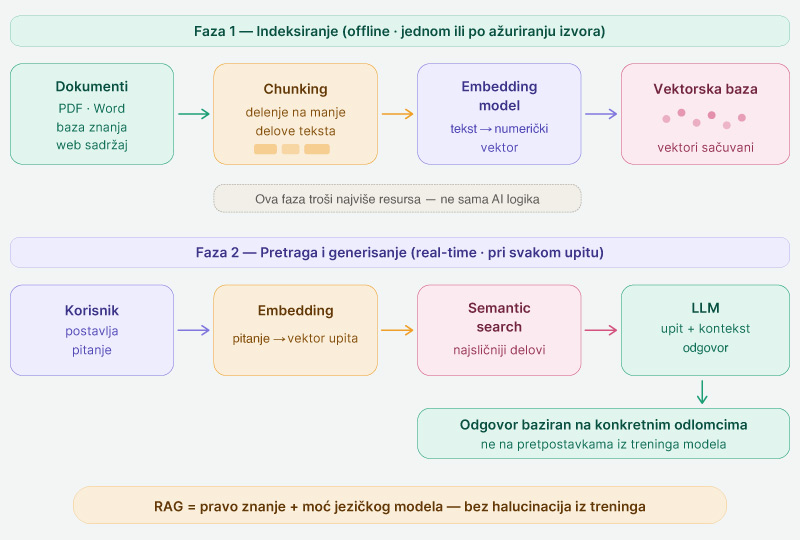
Pre nego što sistem može da odgovori na bilo šta, izvori znanja se pripremaju. Dokumenti se dele na manje delove (chunking), svaki deo se pretvara u numerički vektor pomoću embedding modela, i ti vektori se čuvaju u vektorskoj bazi. Ovo je faza koja troši najviše resursa u praksi, a ne sama AI logika.
Kada korisnik postavi pitanje, sistem pretvara pitanje u vektor, traži najsličnije delove u bazi, i zatim šalje originalni upit zajedno sa pronađenim kontekstom LLM-u tj velikom jezičkom modelu. Model generiše odgovor baziran na konkretnim odlomcima, a ne na pretpostavkama iz svog treninga.
RAG nije zamena za LLM, već način da ga uvežete sa stvarnošću firme. Konkretno rešava tri stalna problema:
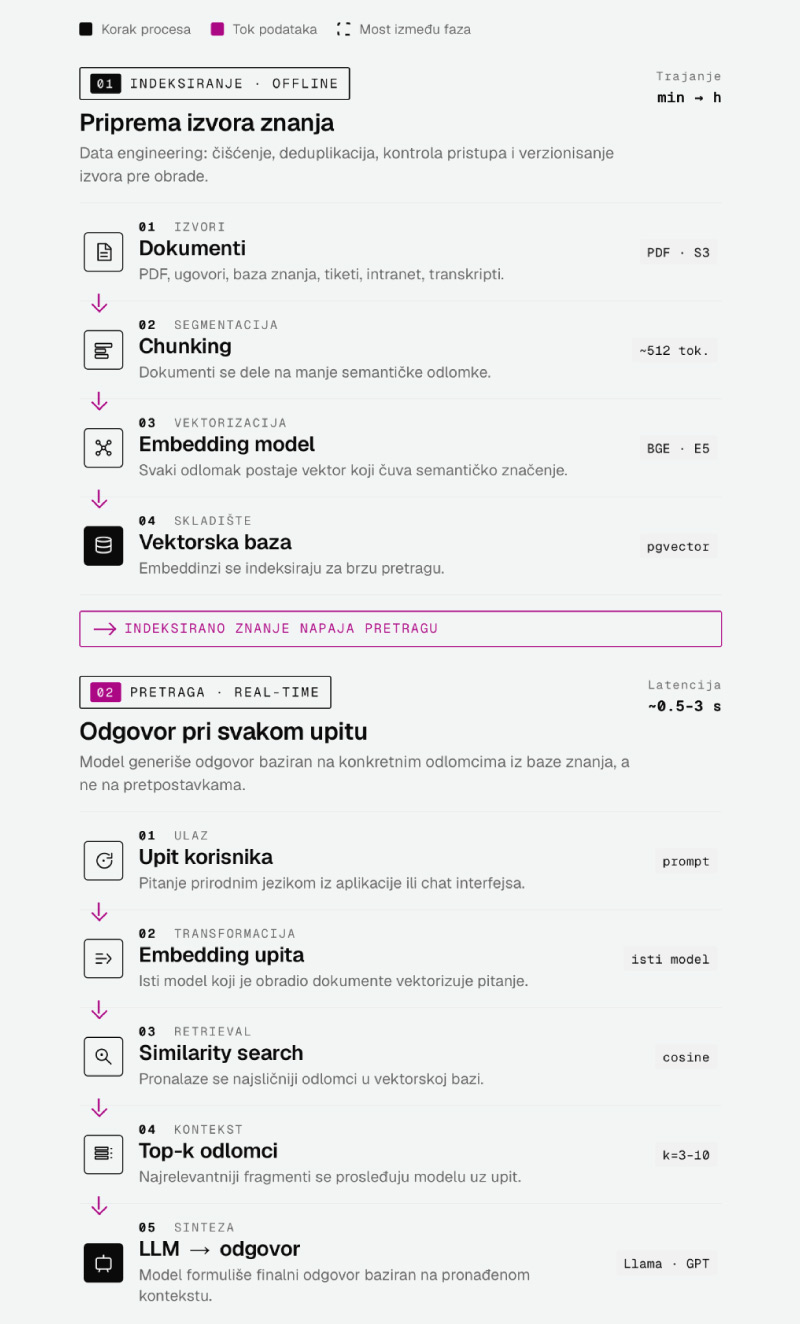
Enterprise RAG sastoji se od pet slojeva, gde svaki od njih nosi tehničku odluku koja kasnije utiče i na kvalitet odgovora i na ukupnu cenu sistema.

U RAG ulaze PDF dokumenti, ugovori, baza znanja, ticketi, intranet stranice, transkripti i strukturirani podaci iz internih sistema. Najveći deo posla nije AI, već data engineering: čišćenje, deduplikacija, kontrola pristupa i verzionisanje izvora. Objektno skladište kompatibilno sa S3 API-jem, poput S3-as-a-Service, standardni je obrazac za izvore pre nego što se obrade i embeduju.
Embedding model pretvara tekst u brojeve koji čuvaju semantičko značenje. Open-source modeli (BGE, E5) rade lokalno bez slanja podataka van organizacije. Komercijalni API-ji (OpenAI Ada, Cohere) su brži za prototip, ali svaki dokument koji embedujete prolazi kroz njihovu infrastrukturu, što je tačka koju često blokiraju pravni timovi.
Vektorska baza čuva embeddinge i pretražuje ih po sličnosti. Opcije zavise od skale i postojećeg stack-a. pgvector je razumna polazna tačka ako već koristite PostgreSQL i imate stotine hiljada dokumenata. Milvus i Weaviate su namenski sistemi koji bolje skaliraju na milijarde vektora. Elasticsearch je dobar izbor ako želite kombinaciju semantičke i pretrage po ključnim rečima u istom sistemu.
Hibridna pretraga (kombinacija dense vektorske i klasične BM25 ključne) je tačka u kojoj većina enterprise RAG sistema postaje stvarno upotrebljiva. Samo semantička pretraga često promaši kada korisnik traži tačan broj ugovora, šifru proizvoda ili specifičan termin.
Pretraga vraća odredjen broj (top-k) najsličnijih delova, ali sličnost nije isto što i relevantnost. Reranker (cross-encoder model) ponovo rangira rezultate tako što pažljivije analizira svakog kandidata u kontekstu konkretnog pitanja. Ovaj sloj najviše utiče na to da li korisnik dobija koristan odgovor ili odgovor koji deluje ispravno ali ne sadrži ono što je tražio..
Na vrhu se nalazi sam jezički model koji formuliše finalni odgovor. Izbor je između javnih API-ja (OpenAI, Anthropic, Google) i self-hosted modela (Llama, Mixtral, Mistral, NVIDIA Nemotron). Self-hosted opcije zahtevaju ozbiljan GPU stack za inference. NVIDIA AI Enterprise stack, koji stoji u osnovi rešenja Platforma+ za enterprise LLM-ove, standardizuje ovaj sloj kroz NIM mikroservise, NeMo Retriever i guardrails komponente, sa referentnom RAG arhitekturom koja se koristi kao polazna tačka u industriji. Orion telekom ovaj stack obezbeđuje lokalno, sa GPU infrastrukturom i podrškom u Srbiji, tako da podaci i obrada ostaju u domaćoj jurisdikciji.
Dva pristupa se često postavljaju kao izbor, ali rešavaju različite probleme.
RAG koristite kada se znanje menja češće nego što biste retrenirali model, kada odgovori moraju biti faktički i potkrepljeni izvorom, i kada želite kontrolu nad tim koje dokumente model „vidi“. Update se svodi na zamenu fajla u izvornom skladištu, ne na novi trening.
Fine-tuning koristite kada želite da model nauči specifičan stil odgovora, format izlaza ili domenske termine. Fine-tuning ne dodaje nova znanja pouzdano; pokušaj da naučite model „činjenicama“ kroz fine-tuning često rezultira halucinacijama jer model uči obrazac, ne podatke.
U praksi, oko 80% enterprise slučajeva spada u RAG. Fine-tuning se koristi kao dodatak, ne zamena, kada se kombinuje sa RAG-om radi specifičnog tona ili strukture odgovora.
Tehnički, RAG je rešen problem. Pravo enterprise pitanje je gde se stack izvršava. Kada šaljete upit javnom LLM API-ju, prompt i retrieved kontekst napuštaju vašu jurisdikciju. Ako taj kontekst sadrži lične podatke kupaca, brojeve ugovora ili interne podatke, svaki upit postaje regulisani transfer podataka.
Po članu 35 GDPR-a, obrada ličnih podataka kroz novu AI tehnologiju u velikom obimu pokreće obavezu izrade DPIA dokumenta (Data Protection Impact Assessment). Evropska konferencija nadzornih organa za zaštitu podataka je 2025. objavila konkretno uputstvo za RAG sisteme u kome se traži klasifikacija svake baze znanja, dokumentacija zakonskog osnova obrade i kontrola pristupa pre nego što sistem uđe u produkciju.
Istovremeno, EU AI Act je stupio na snagu u avgustu 2024, sa obavezama za general-purpose AI modele od avgusta 2025, i punim sankcijama do 35 miliona evra ili 7% globalnog prometa za sisteme klasifikovane kao high-risk. RAG sistemi koji obrađuju lične, medicinske ili finansijske podatke gotovo uvek spadaju u tu kategoriju.
Postoji i tehnički problem koji „EU data residency“ kod američkih provajdera ne rešava: američki CLOUD Act dozvoljava američkim agencijama pristup podacima koji pripadaju američkim kompanijama, bez obzira gde se serveri fizički nalaze. Za regulisane delatnosti, jedini način da se zatvori taj rizik je infrastruktura pod evropskom pravnom kontrolom.
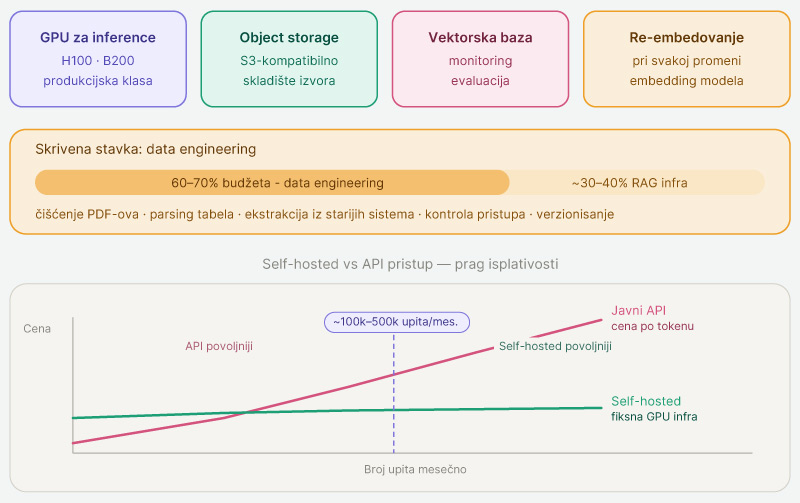
Cena RAG sistema retko se svodi na licencu modela. Glavne stavke su hardver za inference (GPU klase H100 ili B200 za produkciju), object storage za izvore, vektorska baza, monitoring i evaluacija, plus ponovno embedovanje cele baze pri svakoj promeni embedding modela.
Skrivena stavka je data engineering. U većini implementacija, 60 do 70 procenata budžeta odlazi na pripremu izvora: čišćenje PDF-ova, parsing tabela, ekstrakciju iz starijih sistema, kontrolu pristupa i verzionisanje. Sama RAG infrastruktura je manji deo posla.
Suvereno hostovan sistem postaje jeftiniji od API-based pristupa kada broj upita pređe određeni prag, tipično nekoliko stotina hiljada upita mesečno. Ispod tog praga, javni API može biti razumno rešenje za prototip; iznad njega, fiksna cena GPU infrastrukture pobeđuje varijabilnu cenu po tokenu.
Treba razmotriti RAG kada važi nekoliko od ovih uslova:
RAG nema smisla u sledećim slučajevima:
Enterprise RAG je manje pitanje izbora modela, više pitanje izbora infrastrukture. Tehnički delovi (embedding, vector store, retrieval, generation) su standardizovani i opisani u referentnim arhitekturama velikih vendora. Ono što razlikuje funkcionalan sistem od onog kojeg blokira pravni tim je gde se stack nalazi, ko vidi podatke i da li je infrastruktura usklađena sa EU AI Act-om i GDPR-om. Za delatnosti i firme koje čuvaju poverljive podatke, suverena AI infrastruktura sa NVIDIA AI Enterprise stack-om Orion Factory-ja je obrazac koji rešava i tehnička i pravna pitanja u jednom potezu.
RAG povlači eksterne podatke u kontekst pri svakom upitu, dok fine-tuning trajno menja težine modela na osnovu vaših podataka. RAG je jeftiniji za održavanje, podržava česte izmene znanja i daje izvor odgovora. Fine-tuning je bolji za stil i format odgovora, ne za nova faktička znanja.
Sam RAG nije ni usklađen ni neusklađen, to zavisi od toga gde podaci putuju. RAG sistem koji šalje upite javnom LLM API-ju van EU pokreće obavezu DPIA dokumenta po članu 35 GDPR-a, jer prompt i retrieved kontekst često sadrže lične podatke.
Ne postoji jedan tačan odgovor. pgvector je razumna polazna tačka ako već koristite PostgreSQL i imate stotine hiljada dokumenata koje ćete upload-ovati. Milvus i Weaviate su dedikovani sistemi koji bolje skaliraju na milijarde vektora. Elasticsearch je dobar izbor kada želite hibridnu pretragu u istom sistemu.
Da. NVIDIA NIM mikroservisi, NeMo Retriever i open-source LLM-ovi poput Llama 3 i Mixtral mogu da rade u potpunosti on-premise ili na suverenoj cloud platformi. Ovo je standardni obrazac za firme u delatnostima koje ne mogu da šalju podatke javnim API-jima.
Glavni troškovi su GPU za inference, storage za izvore, vektorska baza i data engineering. Za srednju firmu, suvereno hostovani sistem postaje jeftiniji od API-based pristupa kada broj upita pređe nekoliko stotina hiljada mesečno. Skriveni trošak je priprema izvora, koja u praksi uzima 60 do 70 procenata budžeta projekta.

Blog
AI agent je softver zasnovan na velikom jezičkom modelu (LLM) koji samostalno planira i izvršava zadatke kako bi postigao zadati cilj...

Blog
NVIDIA NemoClaw je open-source stack koji platformu OpenClaw za autonomne AI agente pretvara u bezbedno, kontrolisano produkciono okruženje...

Blog
Koliko košta .rs domen u 2026? Maloprodajne cene, nove RNIDS naknade sa PDV-om i skriveni troškovi obnove i transfera. Sve na jednom mestu.