

Datum: 23.07.2026
Šta su AI agenti: vodič za kompanije u 2026.
AI agent je softver zasnovan na velikom jezičkom modelu (LLM) koji samostalno planira i izvršava zadatke kako bi postigao zadati cilj...
Blog
11.06.2026.
Enterprise LLM arhitektura je slojeviti sistem koji omogućava velikom jezičkom modelu (tj LLM-u) da radi u produkciji unutar firme, sa kontrolom nad podacima, troškovima i pristupom. Sastoji se od šest slojeva: data, model, retrieval, orchestration, serving i observability. Razlikuje se od konzumerskog LLM-a po tome što mora da zadovolji regulativu, integraciju sa internim sistemima i merljive SLA.
Većina enterprise LLM projekata propada na prelasku iz POC-a u produkciju. Razlog skoro nikad nije model. Razlog je što tim preskoči dva ili tri sloja koja se ne vide u demo-u. Ovaj tekst razlaže šta čini sistem koji radi stabilno kada počne stvarni saobraćaj.
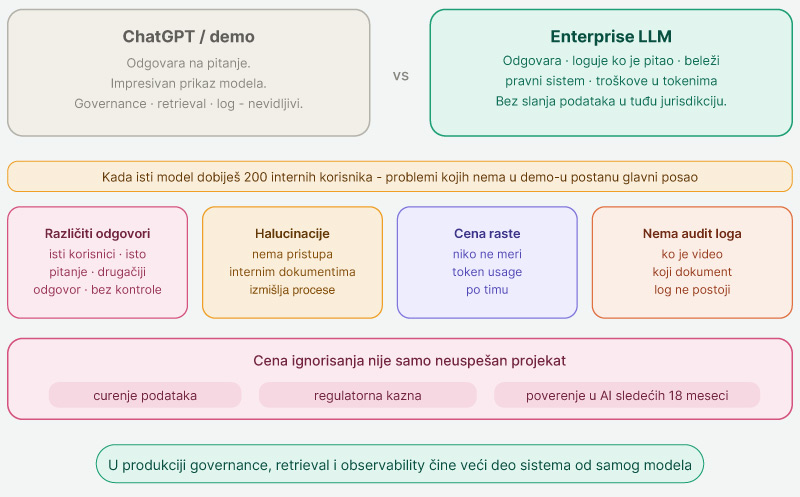
LLM za širu ciljnu publiku odgovara na pitanje. Enterprise LLM odgovara na pitanje, zatim loguje ko je pitao, pod kojim pravnim sistemom je dobio odgovor, koliko je to koštalo u tokenima i da li je odgovor bio tačan. Sve to bez slanja internih podataka u tuđu jurisdikciju.
Demo je impresivan jer pokazuje samo model. Sve ostalo, governance, retrieval, gateway, observability, ne vidi se u demo prozoru, a u produkciji oni čine veći deo sistema.
Zbog toga, kada se isti model stavi pred 200 internih korisnika, problemi koji u demo-u nisu postojali postaju glavni posao tima:
Cena ignorisanja ovih problema nije samo neuspešan projekat. To je curenje podataka, regulatorna kazna i poverenje rukovodstva u AI inicijativu sledećih 18 meseci.

Prvi sloj je gde počinje svaki ozbiljan enterprise LLM projekat. Bez njega ostalih pet slojeva neće biti stabilni.
Data sloj radi tri stvari:
Konkretno pitanje na koje IT direktor mora odgovoriti pre nego što izabere model: gde podaci “žive” kada model počne da odgovara? Ako odgovor uključuje SaaS API u drugoj jurisdikciji, governance sloj mora da ima eksplicitan odgovor zašto je to dozvoljeno. EU AI Act i lokalni Zakon o zaštiti podataka o ličnosti tretiraju procesore podataka strogo, posebno za sektore poput finansija i zdravstva. Više o klasifikaciji jurisdikcije i sloju kontrole možete pročitati u tekstu o suverenoj AI infrastrukturi.
Tim koji preskoči ovaj sloj prvi put, seti ga se kada compliance tim zatraži pun audit trail za odgovor koji je model dao tri meseca ranije.
Najvidljiviji sloj. Paradoksalno, često i najmanje važan za uspeh projekta. Izbor modela retko je razlog zašto sistem radi ili ne radi u produkciji.
Tri realne opcije za enterprise:
Za većinu enterprise scenarija u Srbiji i regionu, druga opcija dobija. Razlog nije ideologija, već to što se podaci ne smeju slati van zemlje, a operativni teret je rešiv ako postoji partner sa GPU infrastrukturom.
Hardverska osnova za model koji ima svoj hosting nije proizvoljna. NVIDIA B200 i prethodni H100 GPU su trenutno realni standard za enterprise inferenciju i trening. U regionu, taj hardver obezbeđuje Orion AI Factory kroz NVIDIA DGX B200 BasePOD sisteme u beogradskom data centru. Softver stack koji ide uz njih, NVIDIA AI Enterprise platforma sa NIM mikroservisima, definiše šta je moguće na model sloju, od kvantizacije do multimodalnih varijanti.
Drugo pitanje koje se vraća: SLM ili LLM? Mali model (Phi, Gemma, Mistral 7B) često je dovoljan za 60 odsto zadataka koje firma stvarno ima, kao što su klasifikacija dokumenata, ekstrakcija polja i kratki odgovori. Veliki model treba samo tamo gde je dokazano da mali ne uspeva. Kreće se obrnutim redosledom: prvo se proba SLM, pa se prelazi na veći model tek kad metrika kvaliteta padne ispod praga.
Ovo je sloj koji pretvara generički model u sistem koji zna nešto o vašoj firmi, bez da ga trenirate.
RAG (Retrieval-Augmented Generation) radi po jednostavnom principu: kada stigne pitanje, sistem prvo pretraži internu bazu znanja, izvuče najrelevantnije delove i preda ih modelu zajedno sa pitanjem. Model odgovara koristeći te delove kao kontekst, sa citatom izvora.
Komponente koje sloj zahteva:
RAG je default za enterprise iz tri razloga: sveži podaci bez ponovnog treninga, izvori za svaki odgovor (audit i poverenje) i niži rizik halucinacije. Pregled standardnih obrazaca, od osnovnog RAG-a do agentic varijanti, daje DZone u svom pregledu LLM arhitekturnih obrazaca.
RAG vs fine-tuning, ovo nije isključivo pitanje. RAG koristite za znanje koje se menja (politike, dokumentacija, ugovori). Fine-tuning koristite za stil, jezik i format odgovora koji ne možete dobiti samo kontekstom. U produkciji često idu zajedno.
Sloj iznad modela. Definiše šta sistem radi sa modelom, ne samo kako mu šalje pitanje.
U najjednostavnijem obliku, orchestration je prompt management: verzionisanje promptova, A/B testovi, evaluacija. To već traži disciplinu. Bez nje, mala izmena prompta na produkciji stvara regression bug koji se teško otkriva.
U složenijem obliku, sloj postaje agent framework. Agent nije model koji odgovara, već sistem koji bira sledeću akciju: pretraži dokument, pozovi API, izvrši kod, traži odobrenje od korisnika, vrati rezultat. Konkretni alati za ovaj sloj uključuju LangChain, LlamaIndex, MCP (Model Context Protocol) i funkcionalne pozive ugrađene u sam model.
Pitanje koje IT direktor mora doneti rano: koliko autonomije sistem ima? AI agent koji samostalno šalje email ili menja zapis u CRM-u nije isto što i chatbot koji vraća odgovor. Granica autonomije je governance odluka, ne tehnička.
Sloj koji LLM tretira kao softver koji mora da radi 24 sata pod opterećenjem.
LLM inferencija nije ista kao bilo koja web aplikacija. Razlog: jedan upit drži GPU memoriju desetinama sekundi, batching je kompleksan, KV-cache zauzima više nego sam model na većem context window-u. Bez razumevanja toga, troškovi rastu nepredvidivo.
Tehničke odluke koje definišu ovaj sloj:
Ovde se prelama odluka o on-prem ili cloud-u. Globalni hyperscaler nudi snagu, ali sa egress troškovima, latencijom od desetine milisekundi do druge regije i pravnim pitanjem gde podaci žive. Lokalna alternativa, kakvu predstavlja Orion AI Factory, drži compute i podatke u istoj jurisdikciji, sa latencijom od jedan do dva milisekunde do AI Factory čvorišta i bez egress naplate.
Realna referentna arhitektura već postoji u Beogradu. Kombinacija NVIDIA DGX B200 BasePOD sistema i NetApp AFF A70 storage-a, instalirana u okviru suverene AI fabrike u Beogradu, pokazuje šta je trenutno mogući standard za enterprise inferenciju i trening u regionu.
AI gateway pattern zaslužuje posebnu pažnju. Umesto da svaki tim u firmi direktno zove svoj model, sve ide kroz centralni gateway koji autentifikuje korisnika, primenjuje rate limit, loguje upite, prebacuje između modela po pravilima i daje jedinstveni audit trail. Bez gateway-a, kontrola troškova i pristupa se deli na desetine mesta.
Sloj koji odvaja sistem koji radi od sistema za koji firma samo misli da radi.
Šta se prati od dana jedan u produkciji:
Bez ovog sloja, svaka izmena u sistemu je rizik bez merljive osnove. Sa njim, postaje moguće sigurno menjati model, prompt ili retriever koristeći blue-green, canary i shadow strategije implementacije, iste tehnike koje DevOps timovi koriste za softverske release-ove, prilagođene da rade sa ML modelima. Za referentnu MLOps praksu, Wikipedia pregled MLOps prakse daje koristan okvir koji se preslikava i na LLM scenarije.
Observability tim retko postoji od prvog dana. Najčešća greška je da se sloj dodaje kada se incident već dogodio. Cena dodavanja naknadno je dva do tri puta veća od cene postavljanja paralelno sa drugim slojevima.
Šest slojeva ne znači šest projekata. Znači šest pitanja na koja arhitekta LLM-a mora imati odgovor pre prvog reda koda.
| Pitanje | Ako odgovor je… | Posledica za arhitekturu |
| Da li podaci smeju da napuste zemlju? | Ne | On-prem ili lokalni provider, ne globalni API |
| Koliko će biti upita dnevno? | Preko 10.000 | Dedicirana GPU infrastruktura, AI gateway obavezan |
| Da li je odgovor regulatorno proverljiv? | Da | RAG sa citatima, pun audit log, observability od dana 1 |
| Da li sistem izvršava akcije ili samo odgovara? | Izvršava | Agent framework + odobrenja + ograničeni autonomy boundary |
Redosled koji u praksi radi: governance i data sloj prvo, retrieval i model paralelno, serving kao treća faza, orchestration tek kada se prvi use case stabilizuje, observability uvek paralelno, nikad kao poslednji korak.
Najčešće greške u regionu: ulazak u fine-tuning pre nego što je korišćen osnovni RAG, izbor modela pre nego što je jasno šta sistem radi, i izgradnja prve verzije bez ikakvog gateway-a.
Plan koji svaki IT direktor može da izvrši pre kraja kvartala:

Arhitektura sistema koji radi u produkciji nije izbor modela. To je redosled odluka o šest slojeva, doneta pre nego što se napiše prva linija integracije. Sistem koji radi je sistem u kome je svaki sloj dobio svog vlasnika i merljiv standard pre nego što su korisnici dobili pristup.
Ako planirate da ovaj proces pokrenete u svojoj firmi, prvi korak je razgovor o use case-ovima i mapiranje slojeva koji već postoje. Orion AI Factory tim radi takve razgovore sa IT menadžerima u Srbiji i regionu i pomaže da se odluke o suverenosti, hardveru i softverskom stack-u donesu pre nego što budžet ode na pogrešnu stranu. Orion AI Factory tim vam stoji na raspolaganju.
ChatGPT je javni servis sa istim ponašanjem za sve korisnike. Enterprise LLM je sistem koji firma kontroliše, sa pristupom internim dokumentima, role-based pravilima, audit logom, definisanim SLA i podacima koji ostaju u jurisdikciji kojoj pripada firma. Razlika nije u modelu, nego u svemu što ga okružuje.
Krenite od RAG-a. Pokriva znanje koje se menja (politike, dokumenti, ugovori) bez retraininga i daje citate izvora. Fine-tuning dodajete tek kada vam treba specifičan stil, jezik ili format odgovora koji se ne može postići kontekstom. U produkciji se često koriste paralelno.
Tri kriterijuma odlučuju: regulatorna ograničenja (smeju li podaci da napuste zemlju), volumen upita (preko 10.000 dnevno menja ekonomiju u korist sopstvene infrastrukture) i latencija (lokalni serving daje 1–2 ms tj 50–200 ms ka udaljenom regionu). Ako bilo koji od ova tri kriterijuma traži veću kontrolu nad podacima ili infrastrukturom, API nije dovoljan..
AI gateway je centralni ulaz preko kog svi pozivi ka jednom ili više modela prolaze. Radi autentikaciju, rate limit, logging i routing između modela. Treba vam čim imate dva tima koja koriste LLM ili dva modela u upotrebi, jer bez njega ne postoji centralna kontrola troškova ni audit trail.
Realistični timing: POC za jedan use case 4–6 nedelja. MVP sa governance slojem i osnovnim RAG-om 3–4 meseca. Puna produkcija sa observability-jem i AI gateway-em 6–9 meseci. Glavni razlog za prekoračenje nije tehnologija, nego nedovoljno rano postavljanje governance i data sloja.

Blog
AI agent je softver zasnovan na velikom jezičkom modelu (LLM) koji samostalno planira i izvršava zadatke kako bi postigao zadati cilj...

Blog
NVIDIA NemoClaw je open-source stack koji platformu OpenClaw za autonomne AI agente pretvara u bezbedno, kontrolisano produkciono okruženje...

Blog
Koliko košta .rs domen u 2026? Maloprodajne cene, nove RNIDS naknade sa PDV-om i skriveni troškovi obnove i transfera. Sve na jednom mestu.