
Datum: 23.07.2026
Šta su AI agenti: vodič za kompanije u 2026.
AI agent je softver zasnovan na velikom jezičkom modelu (LLM) koji samostalno planira i izvršava zadatke kako bi postigao zadati cilj...
Blog
14.04.2026.
Najveća greška je misliti da je LLM deployment samo omogućavanje pristupa modelu kroz API. U praksi, to je problem infrastrukture, performansi i operativnog održavanja koji počinje tamo gde se treniranje završava.
Produkcijski sistem mora da podnese stvarni saobraćaj, garantuje uptime, odgovori u prihvatljivom vremenu i zadovolji bezbednosne zahteve — sve istovremeno, bez degradacije performansi. Taj gap između “radi” i “radi u produkciji” je mesto na kom većina AI projekata zapne.
O tome kako funkcioniše AI Factory kao temelj LLM workload-a, čitajte u zasebnom tekstu.
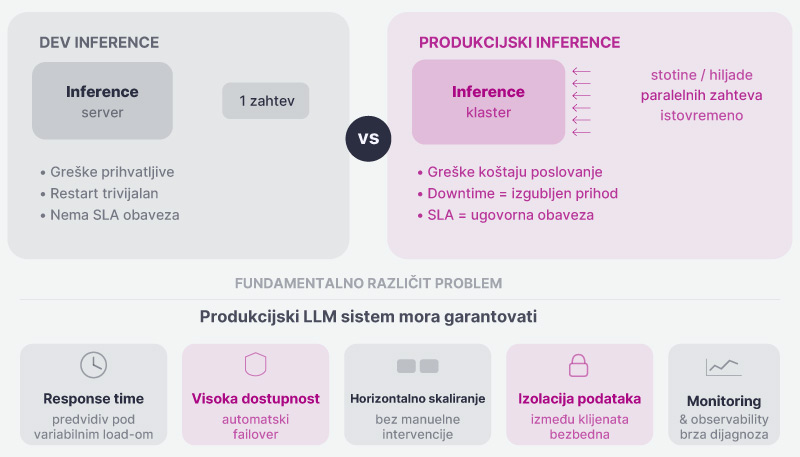
Produkcijski inference nije verzija dev inference-a sa više RAM-a. To je fundamentalno drugačiji problem.
U razvoju, inference server prima jedan zahtev u trenutku, greške su prihvatljive, restart je trivijalan i nema SLA obaveza. U produkciji, sistem mora da procesira stotine ili hiljade paralelnih zahteva, greške koštaju poslovanje, downtime znači izgubljen prihod ili regulatorni problem, a SLA obaveze su ugovorna obaveza.
Konkretno, produkcijski LLM sistem mora da garantuje:
Pre nego što napišete prvu Dockerfile liniju, ova pitanja moraju imati odgovor:
Svaka opcija nosi drugačiji skup kompromisa u troškovima, kontroli i bezbednosti.
vLLM, TGI, Ollama i drugi imaju različite trade-offe u kapacitetu obrade podataka (throughput), latenciji i podržanim modelima.
Full precision (BF16/FP16), quantized (INT8, INT4, GPTQ, AWQ) — izbor direktno utiče na GPU memorijske zahteve i performanse.
Real-time chatbot i batch document processing imaju potpuno različite zahteve. Arhitektura koja se optimizuje za jedno nije optimalna za drugo.
Finansijske institucije, zdravstvo i državni sistemi imaju zahteve koji eliminišu određene deployment opcije od starta.
| Metoda | Prednosti | Mane | Kada koristiti |
| Cloud API (OpenAI, Anthropic) | Nula infra, instant start, state-of-the-art modeli | Token pricing postaje skup pri obimu, podaci idu na tuđe servere, limitirana customizacija | MVP, prototip, startup bez infra tima |
| Self-hosted managed | Balans kontrole i operativne kompleksnosti, vaši modeli | Zahteva DevOps znanje, odgovornost za uptime | Srednje firme sa AI produktom u produkciji |
| On-premise / suvereni | Potpuna kontrola nad podacima i infrastrukturom, predvidivi troškovi, regulatorna usklađenost | Veći upfront trošak, puna odgovornost za održavanje | BFSI, regulisane industrije, AI-first kompanije |
Za kompanije koje žele balans između kontrole i operativne jednostavnosti, čitajte i o prednostima enterprise cloud kao opštoj infrastrukturi.
Svaki izbor znači kompromis. Cloud API je dobar za brz start, ali dugoročno postaje skuplji i ne daje kontrolu nad tim gde se vaši podaci procesiraju. On-premise daje maksimalnu kontrolu, ali zahteva infrastrukturnu ekspertizu i inicijalno ulaganje. Managed infrastruktura je balans — i za većinu timova koji ozbiljno rade deployment LLM-a, to je najrealnija opcija.
Tehnička publika razmišlja u sistemima, ne u tekstualnim opisima. Evo kako izgleda tipična produkcijska arhitektura:
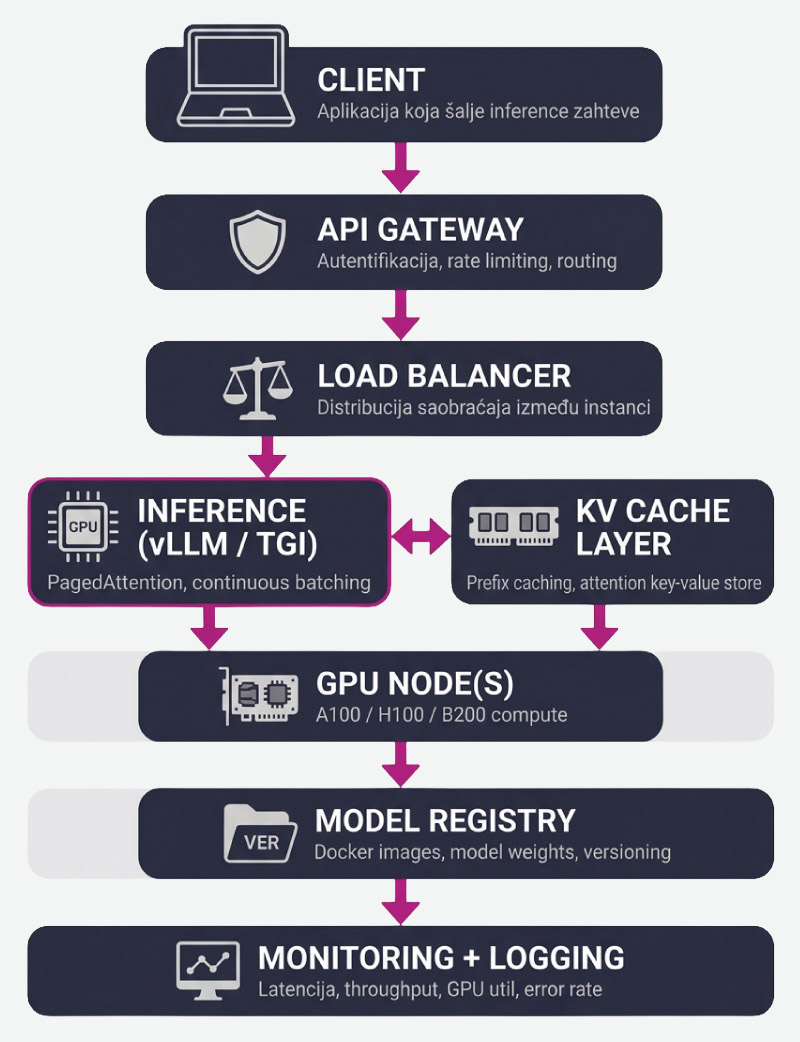
Svaka komponenta ima specifičnu ulogu:
Prima zahteve, autentifikuje ih, primenjuje rate limiting i rutira prema odgovarajućem inference serveru. Ovo je prva linija odbrane i prva tačka observability-a.
Distribuira saobraćaj između inference instanci, detektuje unhealthy instance i omogućava zero-downtime deployment novih verzija modela.
vLLM koristi PagedAttention za efikasan KV cache management i podržava continuous batching – što znači da novi zahtevi ulaze u batch čim prethodni završe, bez čekanja na sledeći batch window. TGI (Text Generation Inference) kompanije Hugging Face je alternativa sa dobrom podrškom za kvantizovane modele i deployment kroz Docker.
Čuva key-value parove iz attention mehanizma za zahteve koji dele isti prefiks, čime se značajno smanjuje opterećenje sistema kod dužih sistemskih promptova.
Služi za čuvanje modela (weights), Docker image-a i konfiguraciju pipeline-a, uz verzionisanje koje omogućava vraćanje na prethodne verzije (rollback) i lakšu integraciju u CI/CD procese.
Prati sve relevantne metrike u realnom vremenu, bez ovoga, deployment je slepilo.
Model i inference server se pakuju u kontejnere kako bi se osigurala konzistentnost i lako premeštanje između okruženja. Docker image obuhvata model (weights) ili način za njegovo preuzimanje iz registra i sve zavisnosti. Kubernetes upravlja instancama, raspodeljuje GPU resurse i automatski ponovo pokreće instance u slučaju greške.
vLLM je trenutno de facto standard za high-throughput inference. PagedAttention eliminiše fragmentaciju memorije. Podržava tensor parallelism za modele koji ne stanu na jedan GPU i ima OpenAI-compatible API što elimininiše potrebu za client-side izmenama.
TGI (Text Generation Inference) je HuggingFace-ov serving framework, dobar za Docker-based deployment i podršku za kvantizovane modele. Nešto lakši za initial setup od vLLM-a.
Ollama je odličan za lokalni development i testiranje, ali nije dizajniran za produkcijski saobraćaj sa više korisnika.
OpenAI-compatible /v1/chat/completions endpoint je takođe de facto standard. Korišćenje ovog formata eliminuje potrebu za izmenom client aplikacija pri promeni modela ili provajdera. Streaming response-i kroz Server-Sent Events (SSE) su obavezni za chatbot use cases.
Horizontal Pod Autoscaler (HPA) u Kubernetesu automatski prilagođava broj inference instanci na osnovu opterećenja GPU-a ili dužine reda zahteva. Moguće je skaliranje od nule do više instanci, ali vreme pokretanja modela (učitavanje weights-a u GPU memoriju) može predstavljati problem kod naglog porasta saobraćaja. To se najčešće rešava održavanjem minimalnog broja aktivnih instanci ili korišćenjem „warm pool“ strategije.
Pre nego što optimizujete, treba da znate šta optimizujete za:
Deployment odluke direktno utiču na ove vrednosti. On-premise infrastruktura u istoj mreži može da dostigne 1-2ms mrežne latencije, dok cloud deployment-i dodaju 20-100ms samo za mrežni RTT.
Kvantizacija smanjuje preciznost težine modela iz BF16/FP16 u INT8 ili INT4. AWQ i GPTQ su trenutno najpopularnije post-training metode kvantizacije koje daju dobar balans između veličine modela i kvaliteta output-a. INT4 quantizacija može smanjiti GPU memorijske zahteve za 4x uz minimalan quality impact za većinu use case-ova.
Continuous batching (za razliku od static batching-a) omogućava inference serveru da dinamički gradi batch-eve od zahteva koji stižu u različito vreme, umesto da čeka na pun batch. Ovo je jedna od ključnih prednosti vLLM-a i drastično povećava GPU korisnost.
Tensor parallelism distribuira model kroz više GPU-ova. Obavezan za modele veće od 70B parametara koji ne stanu na jedan GPU. vLLM podržava tensor parallelism.
Prefix caching čuva KV cache za shared prefix (npr. Dugačak sistem prompt kojeg dele svi zahtevi). Za aplikacije sa fiksnim sistem prompt-om, ovo može smanjiti compute za 30-70% na prvom tokenu.
Ovo je pitanje koje CTO mora da postavi pre odluke o arhitekturi, a ne nakon što infrastruktura bude izgrađena.
GPU infrastruktura je najskuplji deo sistema. H100 GPU u cloud okruženju košta između 3 i 8 USD po satu. Model poput Llama-3 70B zahteva najmanje dva H100 GPU-a za efikasan inference u BF16 preciznosti, što znači 6–16 USD po satu samo za GPU resurse — bez troškova mreže, skladištenja i ostale infrastrukture.
Pogrešno dimenzionisanje sistema ima direktnu cenu: preveliki kapacitet ostaje neiskorišćen, dok premali ne može da podnese opterećenje — u oba slučaja gubi se novac.
Inference optimizacija nije opcija — to je finansijska nužnost. INT4 kvantizacija Llama-3 70B može smanjiti GPU zahtev sa 2x H100 na 1x H100. To je 50% smanjenje infra troška uz minimalan uticaj na kvalitet za većinu use case-ova.
Cloud API vs on-premise — break-even analiza. Cloud API (npr. GPT-4o) košta oko 2.50-10 USD za million input tokena. Za aplikacije sa visokim obimom zahteva, on-premise deployment postaje jeftiniji iznad određenog threshold-a saobraćaja — ali zahteva inicijalnu investiciju u hardver i tim.
Najčešća greška: timovi često predimenzionišu resurse u razvoju (jer je lakše), a zatim pokušavaju da iste konfiguracije prenesu u produkciju bez optimizacije. Rezultat je infrastruktura koja košta 3-5x više nego što je potrebno.

Access control i autentifikacija — svaki API endpoint mora imati autentifikaciju. API ključevi su minimum, OAuth2/JWT je standard za enterprise deployment-e. Rate limiting po korisniku ili organizaciji sprečava zloupotrebe i štiti od prevelikih troškova.
Izolacija podataka — u multi-tenant okruženju, zahtevi različitih klijenata ne smeju da dele KV cache ni logging kontekst. Ovo je posebno kritično za RAG aplikacije gde prompt sadrži osetljive podatke.
Data sovereignty — gde se inference zapravo dešava određuje koji zakoni važe za vaše podatke. Za BFSI i zdravstvo u Srbiji, to znači da inference mora ostati unutar definisane jurisdikcije. Cloud deployment-i kod globalnih provajdera su podložni CLOUD Act-u i sličnim zakonima koji mogu dozvoliti pristup podacima bez vašeg znanja.
Javni API vs privatni L3VPN — za sisteme sa najvišim bezbednosnim zahtevima, javni API endpoint nije opcija. L3VPN sa VRF izolacijom znači da je inference server nevidljiv za javni internet — pristup je moguć isključivo putem privatnih mreža. Ovo je standard koji NBS i slični regulatori zahtevaju za finansijske sisteme.
Više o tome šta je VPN za kompanije i kako funkcioniše, čitajte u zasebnom članku.
Šta pratiti:
Model drift je realan problem za modele koji su podešavani na specifičnim domenskim podacima. Distribucija inputa u produkciji se menja tokom vremena — monitoring output quality-a kroz sampling i feedback ljudi je obavezan za produkcijske sisteme.
CI/CD pipeline za LLM modele mora uključivati: automatsko testiranje novih verzija modela na benchmark setovima pre deployment-a, canary deployment sa postepenim prebacivanjem saobraćaja i automatski rollback na prethodnu verziju ako metrike padnu ispod threshold-a.
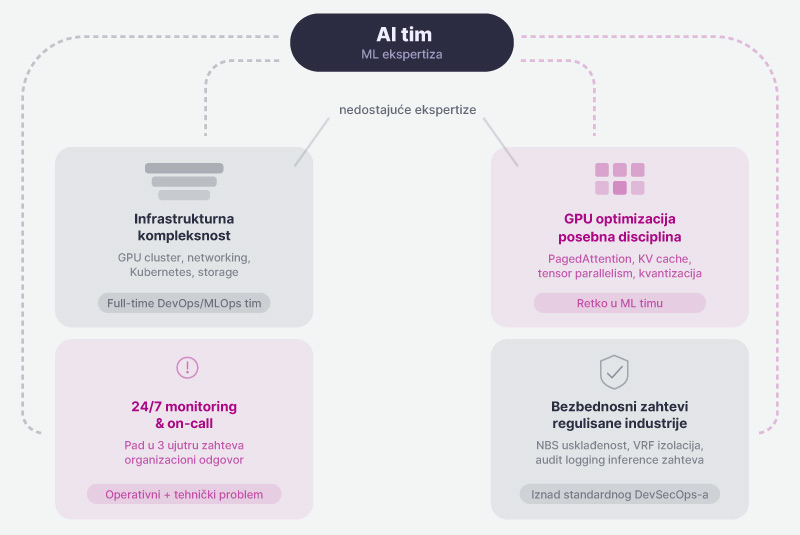
Ovo nije pitanje znanja — većina AI timova ima ML ekspertizu. Problem je u tome što produkcijski LLM deployment zahteva ekspertize koje se retko nalaze u istom timu. Ovo je razlog zbog kojeg sve više kompanija bira gotove enterprise AI platforme.
Infrastrukturna kompleksnost — GPU cluster management, networking, storage optimizacija za model weights, Kubernetes konfiguracija za stateful workload-e. Ovo je full-time posao za DevOps/MLOps tim.
GPU optimizacija je posebna disciplina. Razumevanje PagedAttention-a, KV cache management-a, tensor parallelism-a i trade-offova kvantizacije zahteva specifično znanje koje većina ML timova nema.
24/7 monitoring i on-call — produkcijski sistem koji pada u 3 ujutru zahteva nekoga da odgovori. To je organizacioni i operativni problem, ne samo tehnički.
Bezbednosni zahtevi u regulisanim industrijama su nivo iznad standardnog DevSecOps-a. NBS usklađenost, VRF izolacija, audit logging za sve inference zahteve — ovo zahteva specifično iskustvo sa regulatornim okvirima.
Logičan zaključak: za većinu organizacija, deployment na specijalizovanu infrastrukturu nije kompromis — to je jedini realan put do produkcijskog sistema koji zadovoljava sve zahteve.
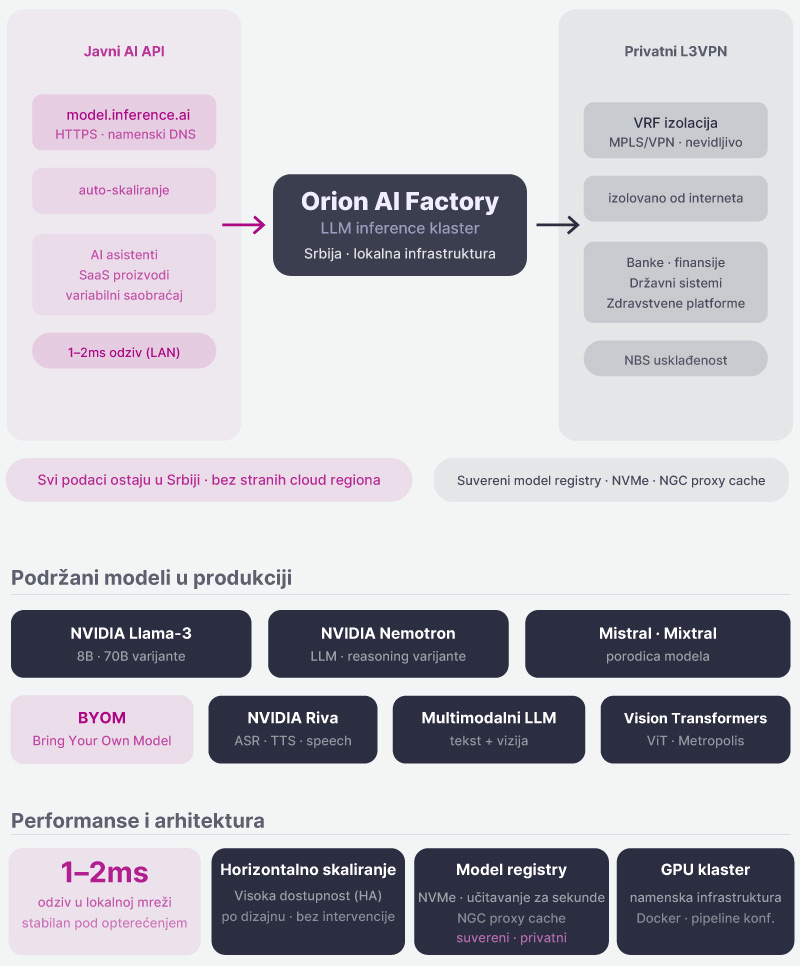
Orion AI Factory Produkcija je infrastruktura dizajnirana specifično za produkcijski LLM inference — ne generički cloud sa AI add-onom, već sistem izgrađen za ovu namenu.
Dva načina pristupa za različite bezbednosne zahteve:
Javni AI API — namenski DNS endpoint (npr. model.inference.ai), HTTPS terminacija, automatsko skaliranje od 0 do N instanci, kontrola opterećenja. Prikladan za AI asistente, SaaS proizvode i aplikacije sa variabilnim saobraćajem.
Privatni L3VPN — potpuno izolovana privatna mreža sa VRF izolacijom, nevidljiva za javni internet, pristup isključivo putem MPLS/VPN veza. Usklađeno sa zahtevima Narodne banke Srbije i državnih regulatora. Standard za banke, finansijske institucije, državne sisteme i zdravstvene platforme.
Više o tome šta je i kako funkcioniše, čitajte u zasebnom članku.
Podržani modeli u produkciji:
Performanse: odziv u 1-2ms u lokalnim mrežama, stabilan response time bez degradacije pod opterećenjem, horizontalno skaliranje i visoka dostupnost (HA) po dizajnu.
Suvereni model registry — vaši model weights, Docker image-i i pipeline konfiguracije čuvaju se u privatnom registru smeštenom neposredno uz compute resurse. NVMe infrastruktura omogućava učitavanje modela za sekunde, NVIDIA NGC proxy cache ubrzava pristup NVIDIA modelima i framework-ovima, bez izlaganja javnim registrima.
Sve, na infrastrukturi koja ostaje u Srbiji, bez oslanjanja na strane cloud regione.
LLM deployment nije završetak AI projekta — to je početak operativne faze koja ima potpuno drugačije zahteve od razvoja i treniranja. Infrastruktura, optimizacija, bezbednost i monitoring su jednako važni kao i kvalitet samog modela.
Timovi koji to shvate na vreme grade sisteme koji funkcionišu u produkciji. Timovi koji to ignorišu dobijaju modele koji rade u demo okruženju, ali ne u stvarnom svetu.
Ako ste pred odlukom o produkcijskom deployment-u, Orion AI Factory Produkcija je infrastruktura koja pokriva tehnički, bezbednosni i regulatorni deo jednačine — tako da vaš tim može da se fokusira na model i aplikaciju.
Zavisi od veličine modela i throughput zahteva. Llama-3 8B u BF16 staje na jedan A100/H100 80GB GPU. Llama-3 70B zahteva minimum 2x H100 u BF16, ili 1x H100 sa INT4 kvantizacijom. Za produkcijske sisteme sa SLA zahtevima, uvek računajte sa redundancijom — minimum 2 instance za HA setup.
Da. Llama-3, Mistral, Mixtral i drugi open-source modeli su u produkciji kod hiljada kompanija. Ključno pitanje nije licenciranje (većina ima permisivne licence za komercijalnu upotrebu), već infrastruktura i optimizacija koja ih čini podobnim za produkciju.
Od nekoliko sati (na managed infrastrukturi sa prekonfiguriranim okruženjem) do nekoliko meseci (interni tim koji gradi infrastrukturu od nule). Ukoliko se odlučite za Orion AI Factory, inference endpoint može biti aktivan istog dana.
Za self-hosted deployment — da, ili bar jedan MLOps inženjer. Za managed infrastrukturu poput Orion AI Factory — ne. Infrastrukturni deo preuzima provajder, vaš tim se fokusira na model i aplikaciju.
vLLM je trenutno superiorniji za high-throughput scenarije zahvaljujući PagedAttention-u i continuous batching-u. TGI je lakši za inicijalni setup i ima dobru podršku za kvantizovane modele. Za produkcijske sisteme sa visokim obimom zahteva, vLLM je češći izbor.
Znate ako su ispunjeni minimalni preduslovi: load test sa realističnim brojem paralelnih zahteva, merenje latencije po percentilima (p95, p99), testiranje failure scenarija (OOM, network timeout), validacija output kvaliteta na hold-out setu i definisani monitoring i alerting pre go-live.
BYOM (Bring Your Own Model) znači da možete uraditi deployment vašeg sopstvenog fine-tuned modela na infrastrukturi provajdera, umesto da koristite jedan od predefinisanih modela. Vaši model weights se uploaduju u privatni registar, a infrastruktura koja servisira ostaje ista. Ovo je ključno za kompanije koje su izgradile domenski specifične modele i žele produkcijsku infrastrukturu bez vezivanja za jednog dobavljača.

Blog
AI agent je softver zasnovan na velikom jezičkom modelu (LLM) koji samostalno planira i izvršava zadatke kako bi postigao zadati cilj...

Blog
NVIDIA NemoClaw je open-source stack koji platformu OpenClaw za autonomne AI agente pretvara u bezbedno, kontrolisano produkciono okruženje...

Blog
Koliko košta .rs domen u 2026? Maloprodajne cene, nove RNIDS naknade sa PDV-om i skriveni troškovi obnove i transfera. Sve na jednom mestu.