

Datum: 16.06.2026
Registracija domena: kako izabrati ime, ekstenziju i pravi paket za vaš biznis
Vodič kroz registraciju domena za poslovne sajtove: kako izabrati ime, ekstenziju (.rs vs .com), dokumentaciju, cenu i provajdera.
Blog
18.06.2026.
Biznis raste, traffic raste, AWS račun raste još brže. Pitanje za većinu IT lidera u 2026. nije više da li skalirati cloud infrastrukturu, već kako da skaliranje ne pojede maržu i ne sruši aplikaciju u trenutku kad treba da radi.
Skaliranje cloud infrastrukture znači prilagođavanje računarskih, mrežnih i storage resursa stvarnom opterećenju aplikacija, automatski ili planirano. Cilj je da sistem podrži rast saobraćaja, korisnika i podataka bez gubitka performansi i bez plaćanja resursa koji se ne koriste. Skaliranje se izvodi horizontalno (dodavanjem instanci) ili vertikalno (povećavanjem postojećih).
Tehnologija i alati su tu već godinama. Greška većine timova nije u alatima, već u logici: kreću da skaliraju u trenutku krize, umesto da arhitekturu pripreme unapred. Ovaj tekst vodi kroz odluke koje stoje iza tih alata.
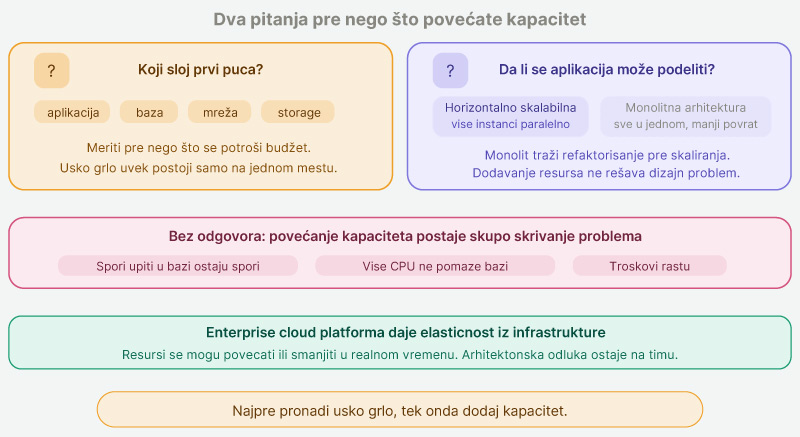
Kompanije koje već koriste enterprise cloud platforme dobijaju elastičnost iz same infrastrukture. Resursi se mogu povećati ili smanjiti u realnom vremenu. Ali odluka kada, koliko i na kom sloju skalirati i dalje pada na tim.
Skaliranje zato nije operativni zadatak, već arhitektonska disciplina. Pre nego što povećate kapacitet, postavite dva pitanja. Prvo: koji sloj zaista prvi puca pod opterećenjem (aplikacija, baza, mreža, storage)? Drugo: da li je aplikacija dizajnirana tako da može da se podeli na više instanci koje rade paralelno, ili je toliko jednoobrazna (sve funkcije u jednom velikom kodu, sa jednom bazom i jednim procesom) da svako dodavanje resursa daje sve manji povrat?
Bez odgovora na ova pitanja, povećanje kapaciteta postaje skupo skrivanje problema. Spori upiti u bazi ne nestaju ako serveru daš više CPU-a. Povećavaju se samo troškovi.
Postoje dva fundamentalna pristupa. Razumevanje razlike određuje sve dalje odluke o arhitekturi i budžetu.
Vertikalno skaliranje znači jačanje jedne mašine. Više CPU jezgara, više RAM-a, brži disk. Pristup je jednostavan, ne traži preraspodelu saobraćaja, i radi sa aplikacijama koje nisu dizajnirane za distribuciju.
Ograničenja brzo postaju ozbiljna. Svaka mašina ima fizički maksimum. Većina upgrade-ova zahteva restart, što znači downtime. Hardverski kvar znači potpuni prekid rada, jer ne postoji rezervna instanca koja preuzima saobraćaj. Zbog toga je vertikalno skaliranje korisno za kratkoročno povećanje kapaciteta ili za workload-e koji se ne mogu distribuirati (legacy aplikacije, određene relacione baze).
Horizontalno skaliranje znači dodavanje instanci. Saobraćaj se distribuira preko load balancera, fault tolerance raste sa svakim novim čvorom, i teoretski nema gornje granice.
Cena tog modela je kompleksnost. Aplikacija mora da bude bez lokalno čuvanog stanja (na engleskom stateless — što znači da nijedna instanca ne čuva sesije korisnika, košarice, fajlove ili tokene samo kod sebe), ili da to stanje deli preko zajedničkog spoljnog sloja. Taj sloj je najčešće baza podataka (gde se čuvaju trajni podaci) ili in-memory keš poput Redisa (servis koji čuva privremene podatke u radnoj memoriji za vrlo brz pristup). Bez ovoga, korisnik koji se prebaci sa jedne instance na drugu izgubi sesiju, košaricu ili upload u toku.
Konfiguracija mora da bude automatizovana, jer ručno provizioniranje deset ili sto instanci nije održivo. Monitoring postaje obavezan, ne opcioni. Zato horizontalno skaliranje funkcioniše tek kad arhitektura sazri.
| Kriterijum | Vertikalno | Horizontalno |
| Brzina implementacije | Brzo | Sporije (zahteva refactor) |
| Downtime | Često prisutan | Bez downtime-a |
| Fault tolerance | Nizak | Visok |
| Maksimalni kapacitet | Ograničen hardverom | Praktično neograničen |
| Profil troška | Predvidljiv, viši po instanci | Granularan, raste linearno |
| Kompleksnost upravljanja | Niska | Visoka |
| Tipičan slučaj | Legacy aplikacije, baze | Web aplikacije, API servisi, micro servisi |
U praksi, savremene cloud arhitekture koriste horizontalno skaliranje kao primarni pristup za elastičnost, a vertikalno kao dopunski metod za specifične komponente.
Auto-scaling automatizuje deo koji bi inače pao na inženjera. Sistem prati metrike i sam dodaje ili uklanja resurse prema definisanim pravilima. Postoje četiri tipa.

Sva tri velika provajdera imaju cloud-native auto-scaling: AWS Auto Scaling Groups, Azure Virtual Machine Scale Sets, Google Cloud Managed Instance Groups.
Za radna opterećenja koja se sastoje od mnogo malih servisa (microservices, containerized aplikacije), orkestracioni sloj postaje obavezan. Kubernetes platforma za automatsko upravljanje kontejnerima skalira na nivou poda — pod je najmanja jedinica u Kubernetesu, obično jedan ili više povezanih kontejnera koji zajedno čine deo aplikacije. Komponenta koja se zove Horizontal Pod Autoscaler automatski dodaje ili uklanja podove na osnovu opterećenja (npr. CPU, memorije ili broja zahteva). Skaliranje na nivou poda je granularnije i jeftinije od skaliranja celih virtuelnih mašina, jer se dodaje samo onoliko kapaciteta koliko jednom servisu zaista treba.
Većina razgovora o skaliranju vrti se oko računarskih resursa (procesor i memorija). U praksi, prvi sloj koji pukne često je storage ili mreža.
Tradicionalni blok-storage skalira teško: dodavanje diskova zahteva planiranje, migraciju, ponekad i downtime. Object storage rešava taj problem dizajnom. S3-as-a-Service rešenje i druge object storage opcije rastu bez ručne intervencije, naplaćuju se po stvarnoj potrošnji, i podržavaju paralelni pristup iz proizvoljnog broja klijenata.
Mreža je drugo nevidljivo usko grlo. Aplikacija koja zavisi od javnog interneta za komunikaciju sa cloud provajderom u jednom trenutku počinje da gubi performanse zbog latencije, nepredvidljivosti i throughput-a. Hibridne arhitekture koje koriste AWS Direct Connect za direktnu konekciju između on-prem infrastrukture i AWS-a eliminišu javni internet kao varijablu. Latencija postaje predvidljiva, throughput se garantuje, a osetljivi podaci ne prolaze javnom mrežom.
Pravilo prakse: kada planirate skaliranje, ne gledajte samo CPU grafove. Pratite I/O na disku, latenciju baze, mrežni throughput. Bottleneck se obično krije na sloju koji niko ne meri.
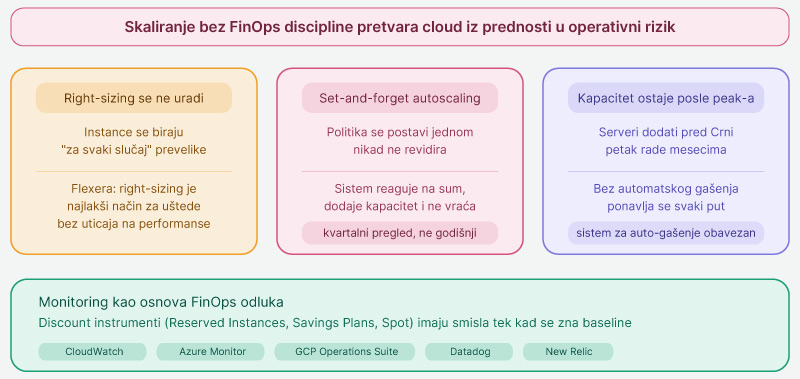
Skaliranje bez FinOps discipline pretvara cloud iz prednosti u operativni rizik. Tri obrasca prave većinu prekomerne potrošnje.
Dimenzionisanje resursa (right-sizing) se nikad ne uradi. Instance se biraju “za svaki slučaj” prevelike. Flexera, softverska kompanija specijalizovana za upravljanje cloud troškovima i FinOps, u svojim analizama navodi da je pravilno dimenzionisanje instanci jedan od najjednostavnijih načina za smanjenje troškova bez uticaja na performanse.
Set-and-forget auto-scaling. Politika se postavi jednom i nikad ne revidira. Sistem reaguje na šum (kratke špiceve), dodaje kapacitet, i zaboravlja da ga vrati nazad. Auto-scaling politike zahtevaju kvartalni pregled, ne godišnji.
Kapacitet ostaje dostupan posle peak-a. Tim ručno doda servere pred Crni petak ili veliku migraciju, i mesecima kasnije ti serveri još uvek rade. Bez sistema za automatsko gašenje, ovo se ponavlja svaki put.
Discount instrumenti (Reserved Instances, Savings Plans, Spot instance) imaju smisla tek kad se zna baseline. Zato monitoring nije opciona stavka. CloudWatch, Azure Monitor, Google Cloud Operations Suite, ili nezavisni APM alati (Datadog, New Relic) daju podatke na osnovu kojih FinOps tim donosi odluke.
Pet obrazaca se ponavlja u skoro svakoj kompaniji koja skalira pod pritiskom umesto plana.
Svaka od ovih grešaka je posledica organizacionog problema, ne tehničkog. Skaliranje funkcioniše kad infrastruktura, DevOps, security i finansije gledaju iste metrike.

Plan ne mora da bude komplikovan da bi bio efikasan.
Kompanije koje žele da preskoče internu krivu učenja često se okreću eksternom timu. Fully managed usluga Orion telekoma Enterprise Cloud pokriva strategiju, migraciju, optimizaciju troškova i 24/7 monitoring uz garantovanu dostupnost od 99,99%, sa sertifikovanim inženjerima koji rade kao produžetak internog tima. Za kompanije koje skaliranje vide kao stratešku, a ne tehničku odluku, eksterni partner skraćuje put od nekoliko meseci do nekoliko nedelja.
Skaliranje znači prilagođavanje cloud resursa stvarnom opterećenju, automatski ili planirano. Cilj je da aplikacija podrži rast korisnika, saobraćaja i podataka bez gubitka performansi i bez plaćanja neiskorišćenog kapaciteta. Izvodi se horizontalno (više instanci) ili vertikalno (jača jedna instanca).
Vertikalno skaliranje (scale up) povećava resurse postojeće instance, što je jednostavno ali ograničeno fizičkim maksimumom hardvera i obično zahteva downtime. Horizontalno skaliranje (scale out) dodaje nove instance i distribuira saobraćaj preko njih, što daje elastičnost i fault tolerance, ali zahteva da aplikacija bude dizajnirana za distribuciju.
Ne automatski. Automatsko skaliranje smanjuje overprovisioning samo ako su politike pažljivo podešene i redovno revidirane. Set-and-forget auto-scaling sa preosetljivim trigerima i zaboravljenim gornjim granicama ume da košta više nego manuelno skaliranje kojim se dobro upravlja. Ključ je periodični pregled politika i pravo merenje koristi.
Hibridna arhitektura je opravdana kada deo workload-a mora da ostane on-prem (zakonski razlozi, niska latencija, osetljivi podaci), a peak ili manje kritični delovi mogu da idu u public cloud. Za ozbiljnu produkciju, ovakva arhitektura traži direktnu mrežnu konekciju ka cloud provajderu, jer javni internet nije dovoljno predvidiv.

Blog
Vodič kroz registraciju domena za poslovne sajtove: kako izabrati ime, ekstenziju (.rs vs .com), dokumentaciju, cenu i provajdera.

Blog
Praktičan vodič kroz arhitekturu enterprise LLM sistema. Šest slojeva koji odvajaju POC od produkcije. Za CTO i IT direktore.

Blog
Kako jedan klik na phishing link postaje upad u celu IT infrastrukturu. Vodič kroz lanac kompromitovanja sistema za B2B sigurnosne timove.